- Définir les étapes du développement du Web.
- Maîtriser les renvois d’un texte à différents contenus.
- Distinguer ce qui relève du contenu d’une page et de son style de présentation.
- Étudier et modifier une page HTML simple.
- Décomposer l’URL d’une page.
- Reconnaître les pages sécurisées.
- Décomposer le contenu d’une requête HTTP et identifier les paramètres passés.
- Inspecter le code d’une page hébergée par un serveur et distinguer ce qui est exécuté par le client et par le serveur.
- Mener une analyse critique des résultats fournis par un moteur de recherche.
- Comprendre que toute requête laisse des traces.
- Maîtriser les réglages les plus importants concernant la gestion des cookies, la sécurité et la confidentialité d’un navigateur.
Développement du web
À partir du milieu du XIXe siècle, les échanges entre « savants » (chercheurs) du monde entier sont devenus de plus en plus faciles avec le développement des transports (trains, bateaux à vapeur, moteur à essence, voiture, avions…) et des moyens de communication (télégraphe, téléphone et internet).
Quand les réseaux informatiques se développent dans la seconde moitié du XXe siècle, les chercheurs rêvent de pouvoir accéder aux informations du monde entier sans avoir à bouger de leurs bureaux et ainsi d’accéder aux dernières nouveautés de leurs collègues pour développer leurs propres recherches de plus en plus rapidement.
Mais comment accéder à un document qui se trouve sur un ordinateur à l’autre bout du monde de façon simple et sans perdre de temps en recherches.
En 1989 Tim Berners-Lee, chercheur au CERN (centre européen de recherche nucléaire) à Genève, commence à travailler sur l’association entre hypertexte et internet en liant hypertexte, TCP et DNS.
En 1990 il crée l’expression World Wide Web (www) et développe, avec Robert Cailliau les adresses web (url), l’hypertexte transfer protocol (HTTP) et l’hypertexte markup langage (html). Ils créent également un navigateur web, un éditeur et un serveur HTTP. L’ensemble est lancé en 1991.
Hypertexte
L’hypertexte est une liaison entre les textes par l’utilisation de mots clefs (comme les mots mis en évidence dans une page Wikipédia qui vous amènent vers une autre définition).
Le mot hypertexte a été créé en 1965 par Ted Nelson et au départ il sert à relier des documents entre eux sur la même machine. L’idée est de se passer des index, qui permettaient autrefois de retrouver un mot ou un concept dans un livre, en faisant en sorte que le simple clic sur un mot amène directement à une définition plus précise de celui-ci.
Avec les liens hypertextes, la lecture n’est plus linéaire, mais le lecteur peut parcourir un ouvrage numérique en fonction de ses envies et de ce qu’il veut approfondir. C’est sur ce système que s’est basé Tim Berners-Lee en l’étendant au réseau Internet naissant.
HTML et CSS
La base du HTML
Le HTML est un langage constitué de balises qui permettent la mise en page d’un document. HTML signifie HyperText Markup Language, donc langage de description de textes liée avec des balises.
Une page HTML est un code source qui sera interprété par le navigateur web. C’est un simple texte.
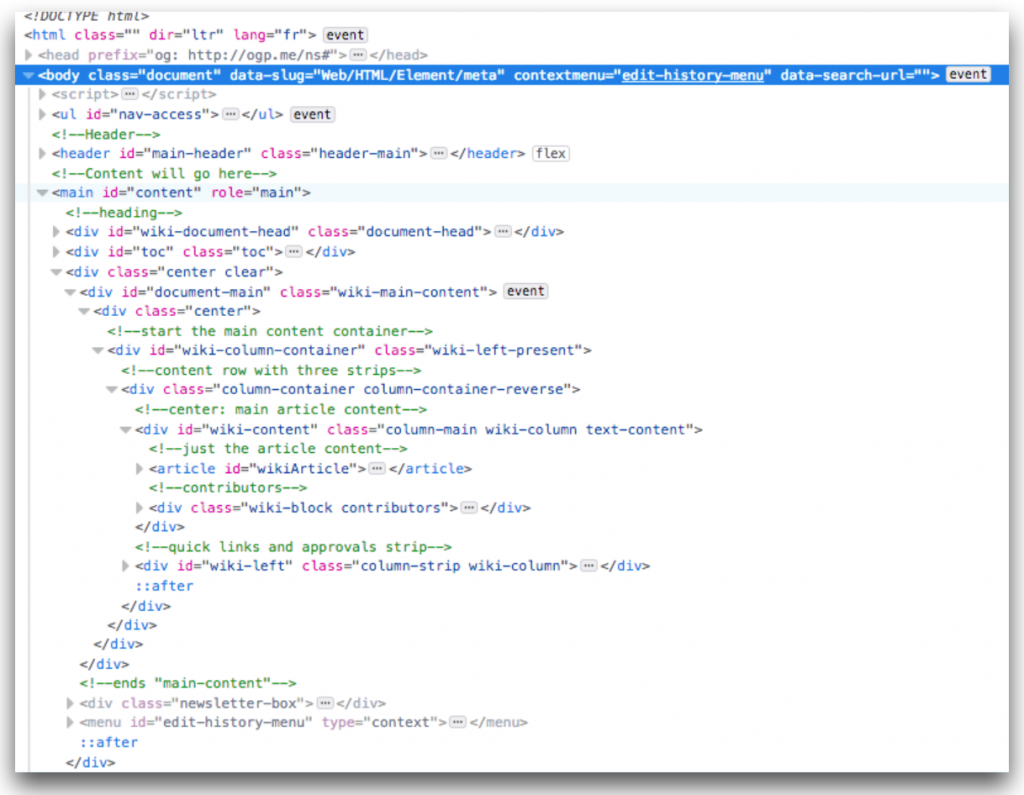
Il est structuré en arborescence avec deux blocs principaux : en-tête et corps.

La structure en arborescence est surtout visible en HTML5 quand on utilise les divisions par contenus (div).
Dans le HTML des premières années du web, il manquait de nombreuses fonctions qui ont été progressivement complétées par le trio HTML+CSS+Javascript :
- Formulaires interactifs
- Achats en ligne (sélectionner des objets, remplir un panier, payer…)
- Mettre des textes en forme, ajouter couleur et mise en valeur…
MAIS il n’était pas possible de créer facilement de l’interactivité avec l’utilisateur pour faire des jeux, écouter de la musique, visionner une vidéo, réaliser une animation pour expliquer un phénomène…
Des greffons (plug-ins) installés dans le navigateur web permettaient d’accéder à ces fonctions. Les plus connus et populaires étaient Flash (racheté par adobe), Silverlight (créé par Microsoft) et Java. Ces greffons ne pouvaient fonctionner que dans une zone prédéfinie de la page.
Les greffons, et particulièrement Flash, le plus populaire d’entre eux, sont devenus de plus en plus puissants et versatiles, mais aussi de plus en plus lourds en temps de téléchargement et de traitement machine.
Les très nombreuses failles de sécurité, qui permettaient de « sortir » du greffon pour accéder à la mémoire d’un ordinateur à distance ont décidé Steve Jobs d’interdire Flash (et les autres) sur les iPhones/iPads. Il a été très vite suivi par Google pour Android.
Dès lors il fallait trouver une manière de faire tout ce que faisaient ces greffons directement avec le HTML, en y ajoutant d’autres fonctions innovantes pour gérer la multitude de nouveaux écrans accessibles.
Apport du HTML 5
- Nouvelles structures de pages pour la hiérarchisation du contenu : <section> <header> <footer> <nav> <article> <aside> <figure>
- Nouveaux éléments de la page : <mark> <time> <meter> <progress>
- Supports améliorés et nouveaux pour des pages web dynamiques : menus contextuels, tableaux liés à des bases de données, <menu> et <command>
- Fonctions supplémentaires pour les formulaires
Le plus important :
- <canvas> pour créer une zone accessible par JavaScript pour y réaliser des dessins, graphes… créés à la volée et interactifs
- <video> pour lire une vidéo dans la page web
- <audio> pour jouer de la musique
Et surtout une ouverture plus grande à l’accessibilité, initiée par HTML 4. Permettant ainsi un accès plus aisé aux personnes handicapées et aux terminaux de toutes sortes : téléphones portables, tablettes, autoradios, réfrigérateurs…
Mettre en forme le texte : CSS
Le formatage d’origine du HTML était très limité.
Le CSS (pour Cascading Style Sheets : feuilles de styles en cascade) permet de réaliser toutes les « folies » de mise en page à l’aide d’un code simple sur une structure simple :
- On déclare quelle balise HTML doit être mise en forme.
- La mise en forme s’effectue alors entre crochets en attribuant des valeurs à certaines propriétés de la balise.

Comme le formatage css est capable de prendre en compte certaines interactions sur la page, en particulier la position de la souris, il est possible de créer une certaine dynamique.
Par exemple, le code ci-dessous change l’apparence du texte quand on passe la souris dessus. C’est un processus très utilisé sur les sites Internet.

Interactivité des pages web
Le JavaScript est standardisé depuis 1997. C’est la troisième brique élémentaire du web actuelle (avec HTML et css).
C’est un langage-objet qui est interprété par le navigateur internet. Cela permet de lire facilement les sources et de s’inspirer de scripts existants pour ses propres pages web.
Les objets sont les éléments d’une page web et le JavaScript permet donc de rajouter de l’interaction par la gestion des évènements (souris, clavier, temps…).
Généralement le code JavaScript est placé dans un fichier à part que l’on prendra soin d’appeler en fin de chargement d’une page afin d’accélérer son affichage initial.
Il est également possible de placer du code JavaScript n’importe où dans une page web.
Avec des extensions de serveur web comme Node.js il est possible d’exécuter du code JavaScript au niveau serveur et de remplacer ainsi le PHP. Cette programmation est de plus en plus populaire (SAP, Microsoft, Sage, Paypal…)

En combinant HTML5, CSS et JavaScript, il est possible de créer des applications entières fonctionnant au sein d’une page web.
Sur téléphone portable (iOS ou Android) il est possible de transformer ces pages web en applications « autonomes » utilisant webkit ou chrome pour l’affichage.
Exemple réalisé en quelques minutes avec Tumult Hype, un IDE pour HTML5/CSS/JavaScript intégrant des bibliothèques de gestion physique (friction, gravité, élasticité…)

Les textes de la profondeur et de la pression sont des objets HTML. Le slider est sur une timeline où l’animation vers le bas est liée au déplacement du plongeur.
Le script suivant modifie la profondeur et calcule la pression correspondante.
La fonction est liée à l’évènement « slide » (glisser) du bouton rond (voir le site cours.jlrichter.fr).
URL
L’URL est un acronyme de Uniform Ressource Locator qui désigne l’adresse d’une ressource sur Internet. Cette adresse se décompose en plusieurs parties qui sont traitées par le serveur visé pour trouver l’information recherchée par l’utilisateur.
Prenons un exemple avec l’adresse du sommaire de ce cours en ligne :
![]()
L’adresse va être lue de gauche à droite.
Protocole
On commence par le préfix « https: » ici. HTTP signifie « hyperText Transfer Protocole » et indique au serveur que l’on cherche une information qui va être une page web en hypertexte (donc en HTML la plupart du temps). Cette première information va aussi indiquer avec quel protocole de communication la page va être traitée.
Le « s » qui suit le HTTP, indique que le transfert se fera de façon sécurisée et que les informations qui transitent sur le réseau pourront être cryptées afin de ne pas être interceptées. Depuis 2017, la plupart des navigateurs, comme Chrome ou Firefox, indiquent clairement les liaisons non cryptées et veulent même que les transmissions en HTTP simple ne soient plus autorisées dans le futur.
Il existe de nombreux autres protocoles que l’on peut retrouver en début d’URL. Par exemple le protocole FTP (File Transfer Protocole) qui est destiné au transfert de fichiers, va commencer avec « ftp: ». l’adresse mail pour l’envoi d’un courrier électronique commencera avec « mailto: »…
Le symbole avec les deux antislash « // » indique que la suite de l’adresse sera le chemin d’accès à la ressource sur le serveur qui va suivre.
Nom de domaine
Comme vu dans le chapitre précédent, la suite de l’adresse, ici « www.cours.jlrichter.fr » est le nom de domaine du serveur auquel on cherche à accéder. Ce nom est relié à une adresse numérique en IPv4 (ou IPv6) et le navigateur fera une requête DNS pour savoir à quelle adresse numérique correspond l’adresse tapée (ou recherchée) par l’utilisateur.
Ce nom de domaine se décompose lui-même en plusieurs parties :
www : indique que l’on cherche le sous-domaine par défaut du serveur web. C’est le plus souvent le cas.
cours : indique que l’on veut accéder au sous-domaine correspondant, sur un serveur qui contient un domaine principal (ici jlrichter.fr) et plusieurs sous-domaines.
jlrichter : est le nom de domaine, dit de second niveau, qui est enregistré au niveau des instances internationales et pourra être retrouvé dans les bases de données DNS.
fr : indique le domaine de premier niveau. Celui-ci est également plus réglementé pour permettre d’identifier facilement la provenance du serveur. Fr indique un serveur enregistré en France. Com indique un serveur commercial. Il existe une très large liste, mais le contrôle n’est pas toujours très bien fait et certains serveurs ne respectent pas les règles. Donc, ne vous fiez pas totalement à ces adresses pour savoir si une adresse correspond bien à ce qu’elle est censée être !
Chemin d’accès
Enfin il faut trouve l’information en question sur le serveur. Pour cela on utilise la suite de l’adresse, ici « /lycee/snt-sciences-numeriques-et-technologie/ ». Cela indique que la page recherchée se trouve dans le répertoire « snt-sciences-numeriques-et-technologie » qui est lui-même dans le répertoire « lycee ».
Notez que toute l’adresse est écrite en minuscule et qu’il n’y a pas de différentiation majuscule/minuscule : toute majuscule est traitée comme une minuscule. Il n’y a pas non plus d’accents ou de caractères spéciaux. Si une adresse souhaite faire appel à des caractères asiatiques, par exemple, elle devra indiquer leur code hexadécimal précédé du caractère « % ».
Autres informations
Une adresse URL peut aussi contenir d’autres informations.
Elle peut, par exemple, commencer avec un nom d’utilisateur et un mot de passe. Mais cette pratique est fortement déconseillée, car ces deux informations sont alors lisibles en clair.
Elle peut également contenir un numéro de port spécifique. Par exemple « https://www.monserveur.com:8080 » enverra la requête sur un port non standard, ici 8080, alors que par défaut une requête https va sur le port 443 (et une requête HTTP sur le port 80). Cela permet de faire fonctionner plusieurs processus sur la même adresse DNS et de donner accès à des ressources différentes selon le port sélectionné. Ces ports spécifiques sont souvent utilisés pour les interfaces d’administration des CMS (Content Management Server, voir plus bas).
En fin d’adresse on peut aussi trouver le nom spécifique d’une page internet, par exemple « https://www.monserveur.com/page1.html » qui enverra vers le document nommé « page1.html » au lieu de « index.html » qui serait la page par défaut.
Enfin on peut profiter de la requête pour envoyer des informations complémentaires au serveur. Par exemple :
« https://www.qwant.com/?q=lyc%C3%A9e%20Schwilgu%C3%A9&t=web »
Ici le point d’interrogation « ? » est suivi d’informations destinées au moteur de recherche Qwant et indique que l’on recherche la page web du « lycée Schwilgué ». Notez comme l’espace entre les deux mots a été remplacé par le code « %20 » et les lettres accentuées par leurs codes respectifs « %C3%A9 » pour « é ».
Requête HTTP
Lorsqu’une adresse URL est validée par un navigateur Internet, celui va effectuer une requête HTTP (HyperText Transfer Protocol) pour demander l’information au serveur.
Les navigateurs modernes permettent de visualiser le contenu de cette demande afin de lire ce qui a été demandé. Voici par exemple une requête vers le site du lycée :

Il existe deux principales méthodes de requêtes : « GET » pour demander une ressource au serveur (page, image, feuille de style…) et « POST » pour transmettre des informations qui devront être traitées par le serveur (un formulaire de commande par exemple). Cette information apparaît en premier dans la requête.
La méthode de communication est suivie de l’URL. On voit dans l’exemple ci-dessus que cette adresse a été traduite en IPv4 par un serveur DNS.
L’en-tête indique également la version du protocole HTTP, 1.1 ici, ce qui représente la dernière version (en 2019), suivi d’un certain nombre de paramètres :

Ces en-têtes indiquent plus précisément quel type de document est demandé (ici on s’attend à du texte ou du HTML et ses variantes), si ces informations peuvent être envoyées sous forme compressée (ici en gzip) ou de quelle page vient l’utilisateur (ici on vient du moteur de recherche Qwant).
Cookies
Afin d’éviter de faire transiter trop d’informations redondantes sur le réseau, un site peut demander au navigateur de conserver en local une partie des données. Celles-ci sont écrites dans un fichier texte nommé « Cookie » qui restera stocké en local jusqu’à ce qu’il soit effacé, soit automatiquement, soit sur demande de l’utilisateur.
S’il permet de faciliter les échanges, ce cookie peut aussi poser un souci de sécurité quand il conserve des données privées d’un utilisateur, surtout si celles-ci sont lues par un autre serveur à qui ces données n’étaient pas destinées !
Modèle client/Serveur
Faire travailler le serveur
L’environnement d’exécution du trio HTML/CSS/JavaScript est très contrôlé : bac à sable, interdiction d’accès aux fichiers…
Il peut être intéressant de modifier une page en fonction d’un contexte (utilisateur, données externes puisées dans une base de données…).
C’est pourquoi, très tôt dans l’histoire du web, des langages de scripts ont été développés pour être exécutés par le serveur AVANT d’envoyer la page générée dynamiquement au navigateur du client.
Le PHP pour PHP Hypertext Preprocessor (encore un acronyme récursif !) est Open Source et domine l’utilisation sur les serveurs internet depuis sa création en 1994.
Sa syntaxe est proche du C et il est interprété par le serveur.
Le code se trouve donc dans la page source sur le serveur, mais ne sera pas visible par le client (qui reçoit la page interprétée).
Scripts serveur en PHP
L’exécution d’un script en PHP nécessite d’installer un serveur web en local pour le développement !
Le serveur le plus simple, et Open Source est Apache. On l’associe au plug-in PHP pour exécuter des scripts côté serveur et à MySQL pour gérer des bases de données sur le serveur.
Pour développer sous Windows on peut installer WAMP (http://www.wampserver.com/) ou EasyPHP (https://www.easyphp.org/)

BDD doudou du PHP
Beaucoup de choses sont possibles en PHP sans base de données (BDD) :
- La gestion de sessions (pour sécuriser des parties d’un site par exemple)
- La gestion des cookies
- L’assemblage d’une page à partir ces sous-éléments : en-têtes, menus, pied de page, contenu… sans réécrire ce code pour chaque page…
Mais l’interfaçage avec une base de données permet encore beaucoup plus :
Créer une seule « page » pour le site pour un contenu qui va se trouver dans une base de données et qui sera appelée selon la demande de l’utilisateur : commentaires, achat en ligne, listes d’élèves…
MAIS : pour accéder aux bases de données il faudra intégrer des requêtes SQL dans le code PHP.

To CMS and beyond
Le fait de pouvoir lire et écrire dans des bases de données sur le serveur, y téléverser des fichiers et en créer de nouveaux par des commandes en PHP a donné naissance à une nouvelle génération de sites internet conçus à l’aide de « Content Management Systems » (CMS) permettant de se concentrer sur le contenu une fois les styles et architectures du site définies.
WordPress, Moodle ou Spip sont des CMS..
Le concept va même plus loin aujourd’hui, car l’interactivité permise par html5/css/JavaScript couplé aux scripts serveur permettent de concevoir des applications complètes en ligne comme Office 365 de Microsoft, la suite office Apple, les applications Google ou encore.. MBN.

Moteurs de recherche
Le moteur de recherche est une invention qui a vraiment révolutionné le web : il permet de retrouver une information précise en peu de temps.. si on sait quelles sont ses limites et comment en tirer le meilleur parti.
Une énorme base de données
Un moteur de recherche est un serveur qui dispose de logiciels fonctionnant en simultanées, nommés « robots d’indexation » dont le rôle est d’explorer tous les sites internet à intervalle de temps régulier et à stocker les mots clefs découverts dans une base de donnée.
Plus cette base de données est importante, plus le logiciel de recherche dans cette base est efficace et meilleure sera la réponse du moteur pour trouver une information particulière.
Effectuer une recherche
La recherche dans une base de donne d’un moteur de recherche se fait sur un ensemble de mots clefs qui doivent être saisi dans un champ texte. Le moteur va ensuite donner des réponses pertinentes (ou pas) si les mots clefs sont bien saisis (sans faute) en fonction d’un algorithme interne, généralement secret, qui va mettre en avant certains sites.
Si les mots clefs sont saisis entre guillemets, le moteur de recherche va rechercher l’expression exacte. Par exemple si on tape simplement « science numérique », un moteur va chercher des sites contenant ces mots dans n’importe quel ordre, même s’ils sont séparés par d’autres mots. Mais « « science numérique » » va chercher un site où ces deux mots apparaissent dans cet ordre.
En plaçant le signe moins « – » devant un mot on indiquera qu’on cherche un site qui ne contient pas le ou les mots qui suivent (si on les met entre guillemets). Certains moteurs de recherche permettent d’aller plus loin dans la personnalisation de la recherche par des formulaires de recherche avancée.
Réponse d’un moteur de recherche
Exemple d’une recherche sur Google sur les mots clefs « cours de physique » :

Il convient d’être très attentif aux réponses données par un moteur de recherche. Vous remarquez ici que le premier lien donné est précédé du terme « Annonce ». Cela signifie que ce site a payé le moteur de recherche pour apparaître en premier dans les recherches et indique donc à coup sûr que celui-ci cherche à se rémunérer sur ses visiteurs.
Ne cliquez donc jamais sur le premier lien sans vérifier que la description correspond à ce que vous cherchez réellement.
Traces sur Internet
À chaque fois que vous effectuez une recherche sur Google ou un autre moteur de recherche, celui-ci va stocker des informations sur cette requête dans un cookie de votre navigateur :

Dans cet exemple, une requête sur les mots clefs « lycée schwilgué » conduit à créer un cookie contenant des informations, incompréhensibles au premier abord, mais qui permettrons à Google d’utiliser cette requête par la suite pour proposer des publicités liées à cette requête ou pour revendre des informations à d’autres annonceurs.
Rien ne reste privé sur Internet sans précaution et cette recherche laisse donc des traces sur votre machine… et sur les serveurs du moteur de recherche.
Utilisation des documents trouvés sur Internet
Une fois que vous avez trouvé une information sur Internet par le biais d’un moteur de recherche ou par un accès direct, respectez les droits d’utilisation de ces informations.
Vous ne pouvez réutiliser une information puisée sur Internet que si l’auteur vous en donne le droit. Il est généralement possible de cibler précisément les informations libres de droits sur votre requête de recherche.
Pour en savoir plus sur vos droits, vous pouvez consulter les documents de la Commission Nationale Informatique et Liberté, la CNIL (https://www.cnil.fr/) et ceux du règlement général sur la protection des données, RGPD (https://www.cnil.fr/fr/rgpd-par-ou-commencer).
Paramètres de sécurités
Lorsque vous utilisez un navigateur Internet, nous avons vu que vous laissez des traces de votre navigation :
- Des cookies contenant toutes sortes d’informations sont stockées et consultables sans que vous ne soyez au courant.
- Les sites que vous visitez sont conservés dans un historique de navigation.
- Vous pouvez stocker des mots de passe pour ne pas avoir à les retaper, parfois même des numéros de carte de crédit. Ces informations peuvent potentiellement être volées par un site web indélicat à la faveur d’une erreur de programmation du navigateur (faille de sécurité).

Paramétrer son navigateur
Pour éviter de laisser trop d’informations privées accessibles à des sites ou des personnes malveillantes, il convient d’abord d’utiliser un navigateur internet récent et à jour et de ne pas y installer de greffons douteux (plug-ins).
Il faut ensuite penser à faire un tour au niveaux des paramétrages du navigateur afin de vérifier que certaines règles de sécurité ont bien été mises en place.
Les écrans suivants viennent de la version 69.0 de Firefox, mais se retrouvent sous une forme semblable sur d’autres navigateurs.
Vous disposez généralement de réglages généraux comme ceux ci-dessous :

On voit ici que le navigateur est réglé sur une configuration « standard » qui bloque les traqueurs connus uniquement en mode privé. Le mode « privé » est un mode où les informations laissées sur le web devraient être minimales, mais il n’assure pas votre confidentialité totale. Il n’autorise pas un site à laisser des cookies accessibles par d’autres sites (cookies tiers) et bloque les mineurs de cryptomonnaies (connus).
Un mode « strict » est possible en bloquant tous les traqueurs et les détecteurs d’empreintes numériques. Il peut être intéressant de l’activer et de vérifier que les sites que vous fréquentez ne sont pas bloqués par ce réglage.
Important : il vaut mieux bloquer trop de sites et débloquer au cas par cas, plutôt que de laisser fuiter vos informations confidentielles !
En dehors de ces réglages généraux, il est important de se rendre dans la partie « Vie privée et sécurité » de votre navigateur afin de vérifier les réglages faits :

On y trouve un bouton pour effacer les cookies et l’historique de navigation, ainsi que les outils de gestions de mots de passe, quand ils existent.
Concernant les mots de passe, pensez à en utiliser un différent sur chaque site que vous fréquentez. Vous pouvez vous aider des gestionnaires de mots de passe de votre navigateur, à condition de ne jamais lui laisser stocker de mot de passe d’un site où vous avez enregistré vos coordonnées bancaires ou de paiement.
Greffons utiles
La plupart des navigateurs permettent d’installer des extensions pour faciliter la navigation. Deux extensions peuvent être intéressantes, à condition de vérifier leur provenance et leurs éditeurs :
- Un bloqueur de publicité : il va limiter la publicité qui s’affiche sur les sites internet en bloquant les requêtes HTTP ou https vers les sites de publicités connus.
- Un bloqueur de cookies et de traqueurs (mouchards) : il va bloquer l’écriture et la lecture des cookies et empêcher qu’un site n’envoie des informations sur votre navigation vers un autre site.
Vous pouvez aussi utiliser le routeur de votre domicile et/ou de votre lieu de travail pour qu’il bloque systématiquement certains sites publicitaires ou douteux afin qu’aucune requête d’aucune machine ne soit possible vers ces sites.
SSL
Des certificats SSL (Secured Socket Layer) permettent d’identifier des sites web lors d’une connexion https. Leur clef publique est stockée en local en même temps que votre clef privée. Ces sites sont identifiés par un verrou vert dans la barre d’adresse qui assure que la connexion est cryptée et potentiellement plus sûr qu’un site qui n’en possède pas. Assurez-vous de sa présence quand vous transmettez des données personnelles ou sensibles, comme des informations de payement.
![]()